Graphiques et analyses
L'analyse des données combine deux outils complémentaires : QGIS pour les opérations spatiales (projection des occurrences, intersection avec le masque amazonien, extraction des listes d'espèces géoréférencées) et R pour les analyses statistiques et la production de graphiques (fréquences des marqueurs moléculaires, diagrammes de Venn, comparaison des deux stratégies de téléchargement).
Analyses spatiales
Projection des coordonnées GenBank, correction des géométries, sélection par localisation sur le masque Amazonie, export des listes d'espèces filtrées.
Analyses statistiques
Calcul des fréquences de gènes, diagrammes de Venn (VennDiagram), comparaison des deux plans de téléchargement, union et différences des listes.
Projection et filtrage spatial sous QGIS
Les coordonnées géographiques extraites des enregistrements GenBank sont exportées en CSV depuis R, puis chargées dans QGIS comme couche de points (CRS : EPSG:4326). Une intersection spatiale avec le masque vectoriel de l'Amazonie permet d'isoler les occurrences situées dans la zone d'étude.
Pipeline QGIS
Export des coordonnées depuis R
Les colonnes ORGANISM, latitude et longitude
sont filtrées et exportées en CSV (genus_coordinates_all_localities.csv
et species_coordinates_all_localities.csv).
Chargement dans QGIS
Les fichiers CSV sont ajoutés comme couches de texte délimité avec
xField = longitude, yField = latitude,
CRS EPSG:4326.
Correction de la géométrie du masque
Le masque amazonien (amapoly_ivb_wgs84.shp) présentait des
géométries invalides. L'outil Réparer les géométries
(Géométrie vectorielle) a été appliqué pour générer amapoly_fixed.shp.
Sélection par localisation
L'outil Sélectionner par localisation (prédicat : intersecte)
est appliqué sur les couches de points avec amapoly_fixed.shp
comme géométrie de référence. Les points sélectionnés correspondent aux
occurrences situées en Amazonie.
Export de la sélection
Les entités sélectionnées sont exportées via Clic droit → Exporter →
Sauvegarder les entités sélectionnées sous…, produisant les fichiers
species_amazonia.csv et genus_amazonia.csv.
Résultats : espèces amazoniennes identifiées
L'intersection spatiale avec le masque amazonien a permis d'extraire deux listes d'espèces géoréférencées en Amazonie, issues respectivement de la recherche par genre et par espèce. Ces deux listes sont ensuite comparées dans R.
Projection des échantillons avant et après filtrage
Les graphes ci-dessous représentes les projection des espèces pour lesquelles les données géographiques sont indiquées dans NCBI. Des 525 espèces identifées dans NCBI seulement 113 sont géolocalisables sur une carte.
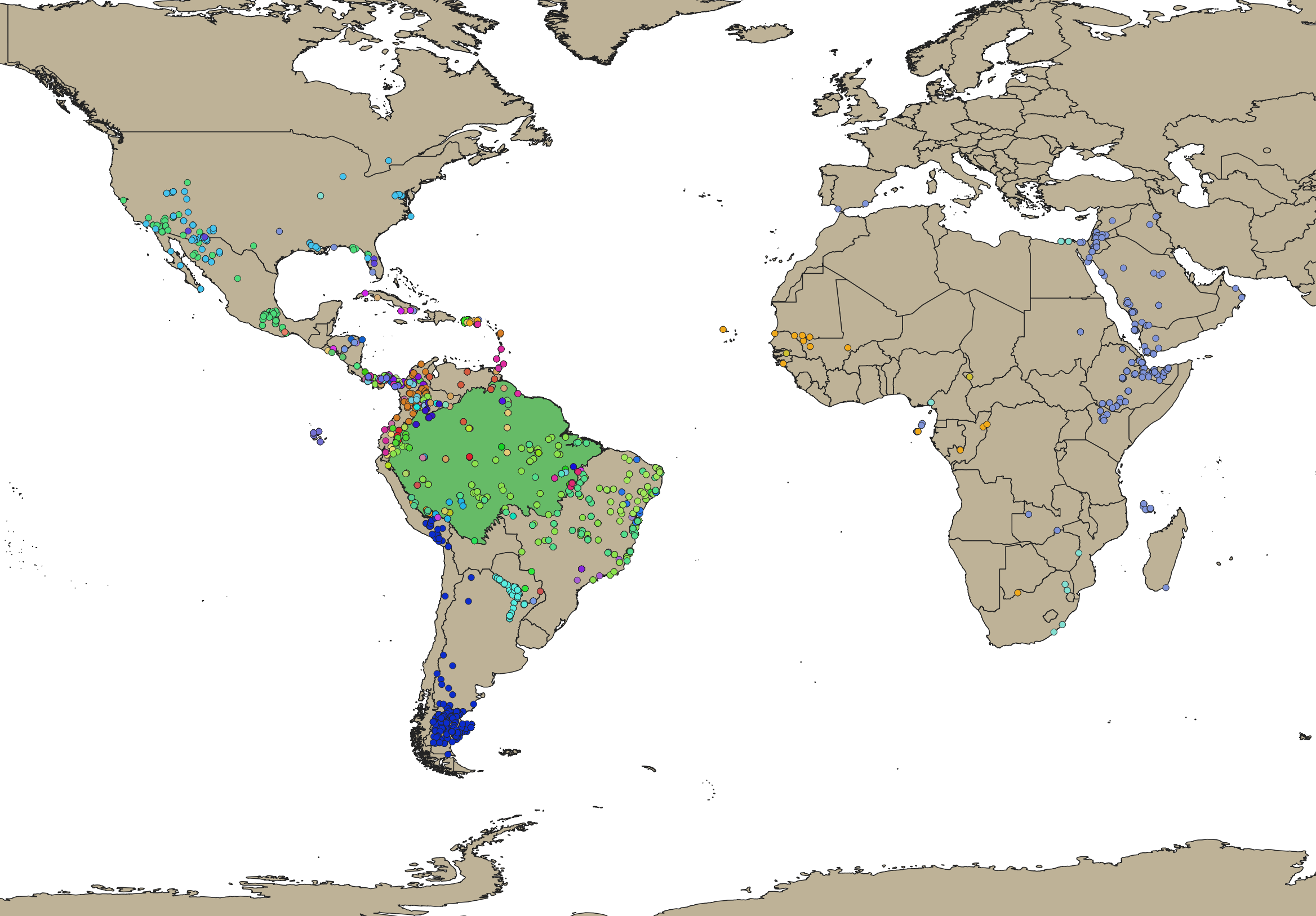
Figure 1. Projection global des espèces identifiées — Nous pouvons observer que pour une recherche large en incluant les genres, nombreux sont les résultats. Pour ce concentrer sur les espèces amazonienne il faut filtrer sur la couche amazonienne (secteur vert)
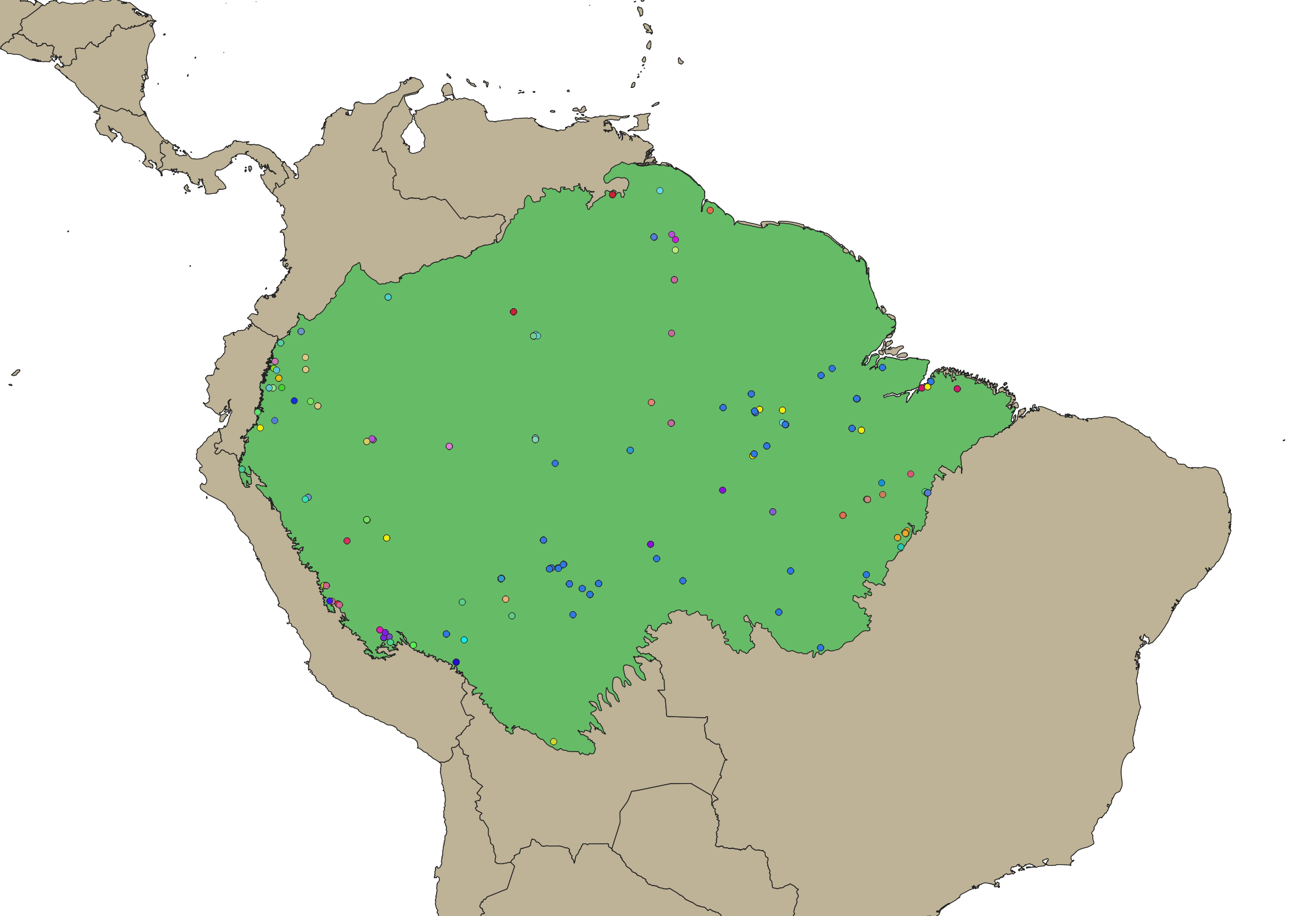
Figure 2. Projection des espèces amazoniennes — Sur cette carte nous pouvons observer les espèces présentes à l'intérieur du périmètre Amazonien. Ces dernières sont colorées par espèces distinctes (113 au total)
Fréquence des marqueurs moléculaires
L'analyse de la fréquence des gènes dans le jeu de données consolidé permet d'identifier les marqueurs les mieux représentés pour les squamates amazoniens. Chaque locus est caractérisé par son nombre d'occurrences et le nombre d'espèces distinctes couvertes, et est coloré selon son origine cellulaire (mitochondrial vs nucléaire).
Top 20 des marqueurs les plus représentés
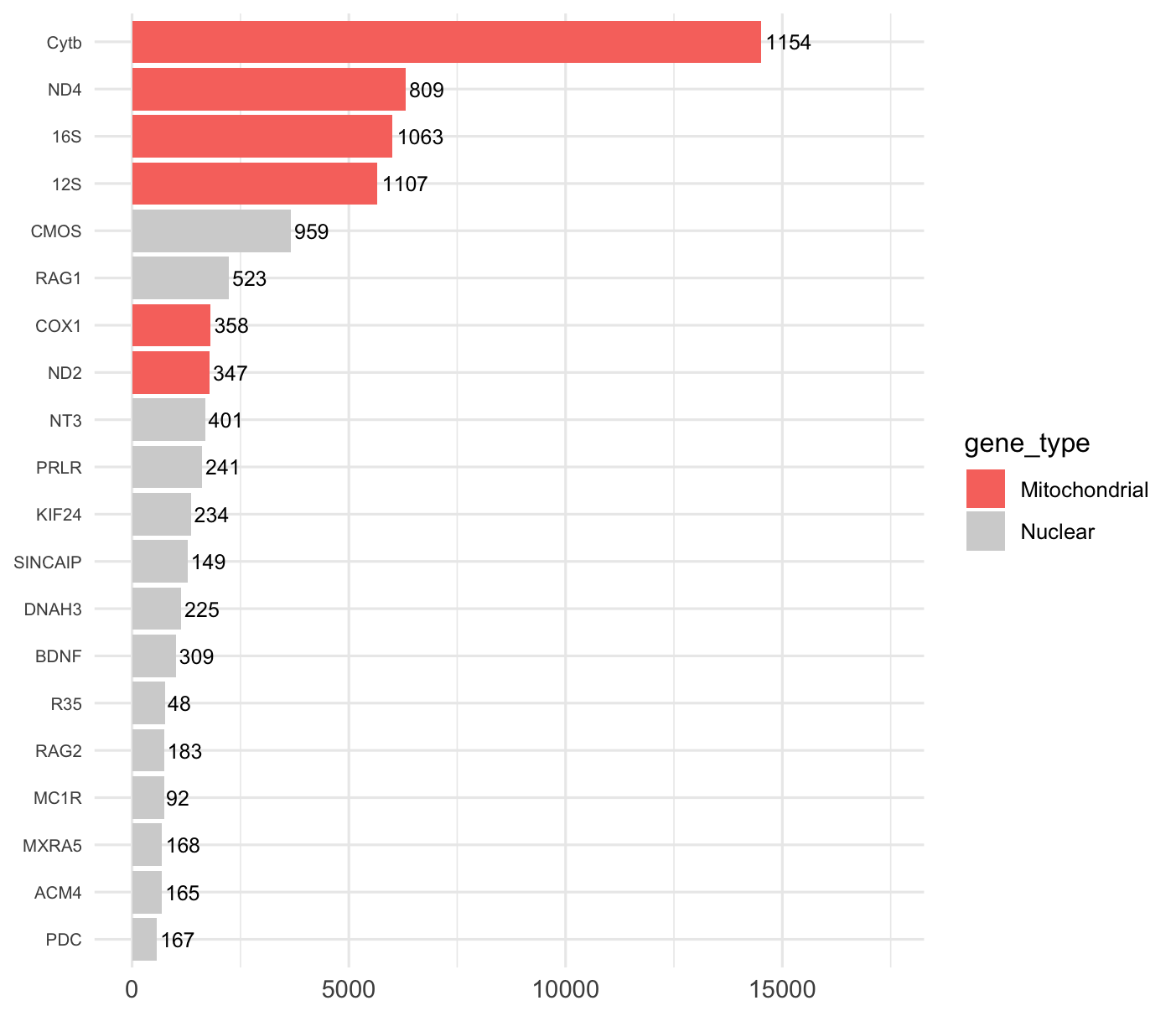
Figure 3. Les 20 marqueurs moléculaires les plus fréquents dans le jeu de données genres. Les barres rouges correspondent aux gènes mitochondriaux, les barres grises aux gènes nucléaires. Les chiffres à droite indiquent le nombre d'espèces distinctes couvertes par chaque marqueur.
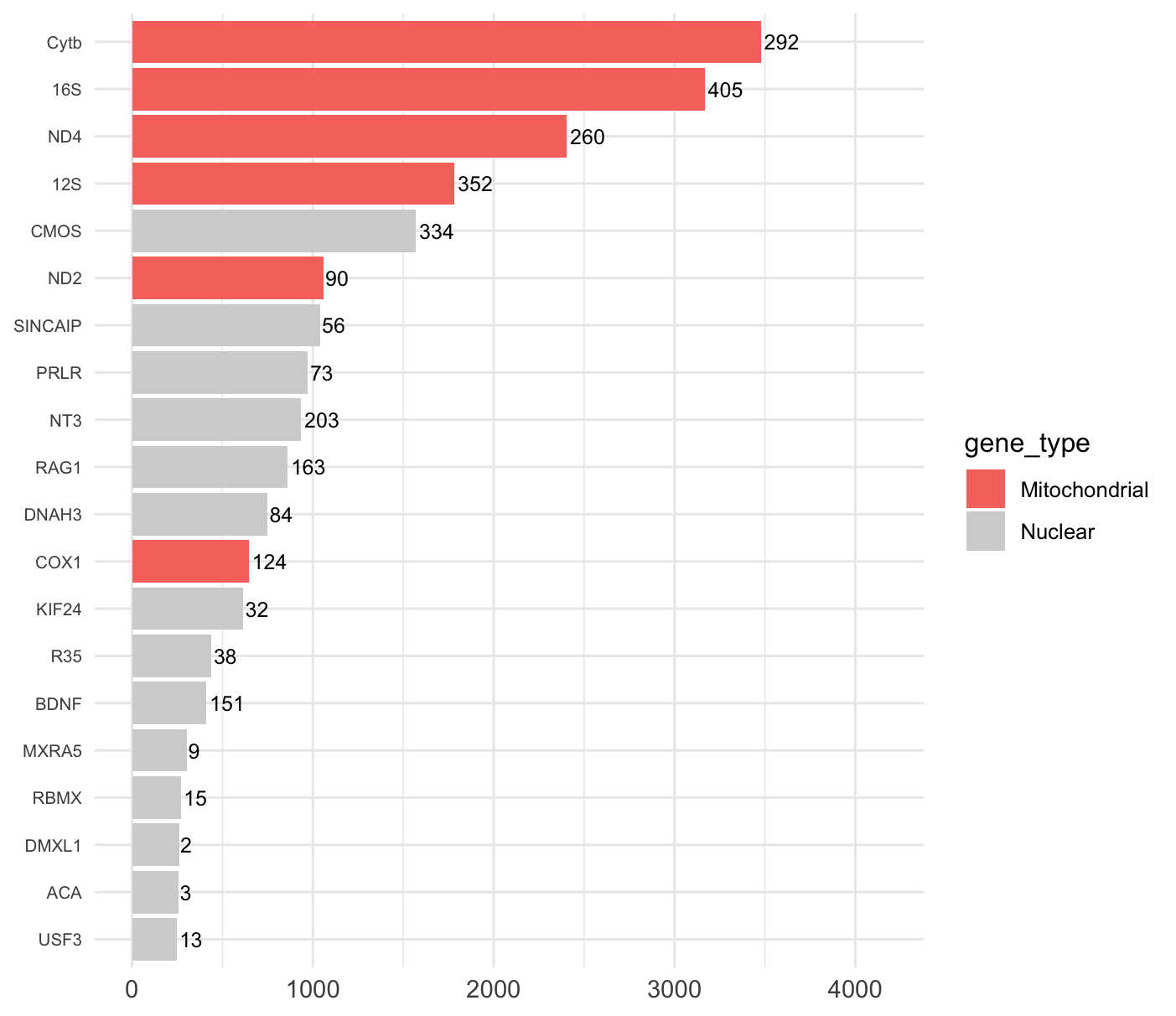
Figure 4. Les 20 marqueurs moléculaires les plus fréquents dans le jeu de données espèces. Les barres rouges correspondent aux gènes mitochondriaux, les barres grises aux gènes nucléaires. Les chiffres à droite indiquent le nombre d'espèces distinctes couvertes par chaque marqueur.
Code R — graphique de fréquence
gene_freq <- COMBINED_GENUS %>%
filter(!is.na(locus), locus != "") %>%
mutate(gene_type = case_when(
grepl("mitochondrion", organelle) ~ "Mitochondrial",
is.na(organelle) ~ "Nuclear"
)) %>%
group_by(locus, gene_type) %>%
summarise(n_occurrences = n(), n_species = n_distinct(ORGANISM))
# Graphique top 20
ggplot(gene_freq_top20, aes(x = n_occurrences,
y = reorder(locus, n_occurrences), fill = gene_type)) +
geom_bar(stat = "identity") +
geom_text(aes(label = n_species), hjust = -0.1, size = 3) +
scale_fill_manual(values = c("Mitochondrial" = "#F8766D", "Nuclear" = "#D3D3D3"))
Les marqueurs mitochondriaux (COX1, Cytb, ND4) dominent très largement le jeu de données, ce qui est attendu pour les squamates.